В 2022 году SSD ноды тем более с 1 диском уже почти не делались.
В основном делались NVME ноды и несколько HDD когда места кончались и приходилось собирать HDD, HDD уже делались на Эпике, а не на старом хеоне, кстати старые HDD ноды прямо все ноды в ошибках уже смердят. Но на удивление все еще работают, буду ждать до конца.
Так что если у вас HDD тариф и который был куплен в 2020 году где-то — вы уже в зоне риска ) Но ведь так веселее, не забывайте делать бекапчики.
Сначала смотрим ноды которые без raid, те самые 6700k c 480 SSD которые все никак не сгорят. Обидно что цены на них повысило ОВХ, из-за этого весь кластер стал не особо выгоден. Плюс еще IP адреса стали платные. И теперь хочется мигрировать уже. Спрос на эту услугу начинает падать, т.к. цену пришлось поднять. А я так хотел дождаться полноценного исхода. Вот скажите, я бы оплачивал по старой цене хоть до 2030 года пока не сгорело бы. Но вместо этого теперь возможно мне придется отказаться от всех этих серверов и ОВХ потеряет прибыль. Стоило ли это повышение цен того? Я думаю не стоило.
noda0 Power_On_Hours — 31962; Written — 410591874672; ТБ = 191.20
noda1 Power_On_Hours — 55797; Written — 1081986797324; ТБ = 503.84
noda2 Power_On_Hours — 54430; Written — 271106052122; ТБ = 126.24
noda3 Power_On_Hours — 41092; Written — 162899712515; ТБ = 75.86
noda4 Power_On_Hours — 44229; Written — 281458678956; ТБ = 131.06
noda5 Power_On_Hours — 58627; Written — 357025109814; ТБ = 166.25
noda6 Power_On_Hours — 41750; Written — 328427799761; ТБ = 152.94
noda7 Power_On_Hours — 47255; Written — 393504839331; ТБ = 183.24
noda8 Power_On_Hours — 38933; Written — 278050093013; ТБ = 129.48
noda9 Power_On_Hours — 44389; Written — 661278434690; ТБ = 307.93
noda10 Power_On_Hours — 58401; Written — 1091944264733; ТБ = 508.48
noda11 Power_On_Hours — 53264; Written — 2542678133898; ТБ = 1184.03
noda12 Power_On_Hours — 51551; Written — 504467695371; ТБ = 234.91
noda13 Power_On_Hours — 57060; Written — 533827478435; ТБ = 248.58
noda14 Power_On_Hours — 58512; Written — 601850919932; ТБ = 280.26
noda15 Power_On_Hours — 44316; Written — 328092008364; ТБ = 152.78
noda16 Power_On_Hours — 56861; Written — 748266774450; ТБ = 348.44
noda17 Power_On_Hours — 53477; Written — 339617346837; ТБ = 158.15
noda18 Power_On_Hours — 55656; Written — 527763932869; ТБ = 245.76
noda19 Power_On_Hours — 49820; Written — 198920236487; ТБ = 92.63
noda20 Power_On_Hours — 44238; Written — 405366210577; ТБ = 188.76
noda21 Power_On_Hours — 57661; Written — 662867455887; ТБ = 308.67
noda22 Power_On_Hours — 69092; Written — 924404160175; ТБ = 430.46
noda23 Power_On_Hours — 70581; Written — 1867349276331; ТБ = 869.55
noda24 Power_On_Hours — 52733; Written — 230277663614; ТБ = 107.23
noda25 Power_On_Hours — 44242; Written — 286390629015; ТБ = 133.36
noda26 Power_On_Hours — 50826; Written — 397791959500; ТБ = 185.24
noda27 Power_On_Hours — 58200; Written — 299447351421; ТБ = 139.44
noda28 Power_On_Hours — 44503; Written — 288120318662; ТБ = 134.17
noda29 Power_On_Hours — 74958; Written — 389161907359; ТБ = 181.22
noda30 Power_On_Hours — 43709; Written — 179282370546; ТБ = 83.48
noda31 Power_On_Hours — 69290; Written — 697618048515; ТБ = 324.85
noda32 Power_On_Hours — 51384; Written — 336112395113; ТБ = 156.51
noda33 Power_On_Hours — 39614; Written — 22741673052; ТБ = 10.59
noda34 Power_On_Hours — 44995; Written — 125938158; ТБ = 64.4
noda35 Power_On_Hours — 58432; Written — 217704720789; ТБ = 101.38
noda36 Power_On_Hours — 71164; Written — 541078819058; ТБ = 251.96
noda37 Power_On_Hours — 55529; Written — 743064659644; ТБ = 346.02
noda38 Power_On_Hours — 58426; Written — 691603995870; ТБ = 322.05
noda39 Power_On_Hours — 57037; Written — 714494720542; ТБ = 332.71
noda40 Power_On_Hours — 27695; Written — 259225918782; ТБ = 120.71
noda41 Power_On_Hours — 56895; Written — 233065961171; ТБ = 108.53
noda42 Power_On_Hours — 53523; Written — 246154674880; ТБ = 114.62
noda43 Power_On_Hours — 56161; Written — 449523978860; ТБ = 209.33
noda44 Power_On_Hours — 63613; Written — 511475618775; ТБ = 238.17
noda45 Power_On_Hours — 52766; Written — 209721240410; ТБ = 97.66
noda46 Power_On_Hours — 44459; Written — 306845352427; ТБ = 142.89
noda47 Power_On_Hours — 56831; Written — 169856827463; ТБ = 79.10
noda48 Power_On_Hours — 51609; Written — 164259051386; ТБ = 76.49
noda49 Power_On_Hours — 52317; Written — 267195834398; ТБ = 124.42
noda50 Power_On_Hours — 47741; Written — 618951020917; ТБ = 288.22
noda51 Power_On_Hours — 69468; Written — 702158822820; ТБ = 326.97
noda52 Power_On_Hours — 44126; Written — 764629007558; ТБ = 356.06
noda53 Power_On_Hours — 65838; Written — 103970475895; ТБ = 48.42
noda54 Power_On_Hours — 46786; Written — 302693213402; ТБ = 140.95
noda55 Power_On_Hours — 54644; Written — 270625014114; ТБ = 126.02
noda56 Power_On_Hours — 43741; Written — 103533275622; ТБ = 48.21
noda57 Power_On_Hours — 55318; Written — 880058803315; ТБ = 409.81
noda58 Power_On_Hours — 69081; Written — 291284516971; ТБ = 135.64
noda59 Power_On_Hours — 57955; Written — 291313485236; ТБ = 135.65
И еще посчитаем SSD E3-1245v2 остатки от прошлого
Новые NVME уже считать после 2025 годов когда они начнут устаревать, щас все новое смысла нет. Если сломается что, тогда уже напишу.
E3-1245v2 часов меньше, т.к. я подбирал с отказов серверы где были новые диски, хотя 1245v2 работают куда дольше у меня на проектах, но время ниже т.к. диски на момент старта были новые.
noda1 Power_On_Hours — 37978; Written — 7403814; ТБ
noda2 Power_On_Hours — 33252; Written — 1431415; ТБ
noda3 Power_On_Hours — 37666; Written — 2399573; ТБ = (4 сектора биты)
noda4 Power_On_Hours — 37809; Written — 176555100148; ТБ = 82.21 (сгорел второй диск из RAID)
noda5 Power_On_Hours — 37512; Written — 3158878; ТБ
noda6 Power_On_Hours — 39184; Written — 4345143; ТБ
noda7 Power_On_Hours — 39751; Written — 3971509; ТБ = (1 сектор бит)
noda8 Power_On_Hours — 39679; Written — 2067511; ТБ
noda9 Power_On_Hours — 50277; Written — 1519204; ТБ
noda10 Power_On_Hours — 37734; Written — 7122129; ТБ
noda11 Power_On_Hours — 35988; Written — 105040480570; ТБ = 48.91
noda12 Power_On_Hours — 39738; Written — 4357967; ТБ
noda13 Power_On_Hours — 38051; Written — 1049804; ТБ
noda14 Power_On_Hours — 37896; Written — 109253838649; ТБ
Остальные были HDD и первые 2 сервера в бедах уже самые первые 2 HDD которые были, но живут еще до сих пор, хотя там смарты ужасно плохие.
А под катом полноценные смарты всех нод.
Но вот сгорел один диск, правда не SSD, а NVME более новый и более современный, всего 2 года отслужил на 4 ТБ диск был. И я вспомнил что давно не проверял SSD где 6700k
Осень 2022 — пятый SMART отчет
Игнорируем все ноды где по 2 диска, смотрим только огнеопасные 6700k где 1 диск всего лишь.
Кстати в 2021 году еще и сам ДЦ SBG сгорел нахуй вместе с некоторыми нодами :) Прямо как я писал — работает, пока не сгорит :)))
Ну так вот смотрим только ноды, где 1 SSD без raid1:
В ОВХ каждая услуга под бесплатным мониторингом от ДЦ.
А кому он не нужен — в ПУ просто его отключают и тогда сотрудники ДЦ не трогают сервер вообще (который кстати меньше сотни обычно, а не по 500 человек как в РФ инженеров)
Так вот, когда в ОВХ сгорает что-то — 15 минут и готово — уже чинят, может быть пол часа, может быть час — все само, все автоматически потом сервер оживет.
А в Хетзнер — ты можешь даже и не знать о том, что сервер сдох.
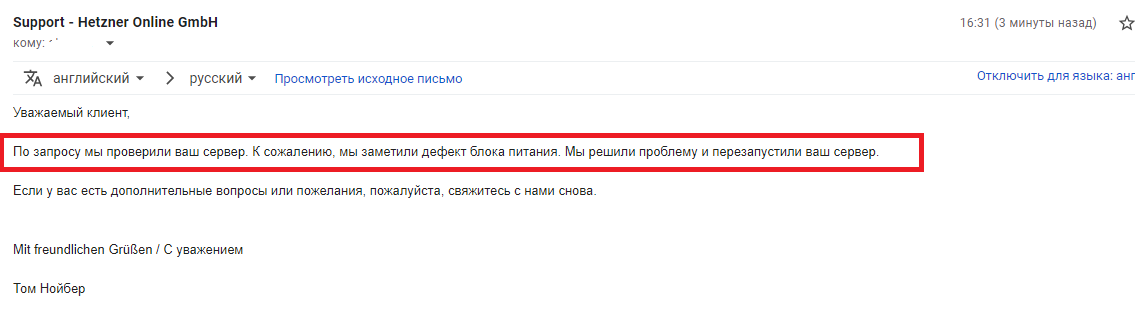
В 10 утра сервер сдох. Если бы у меня не было своего мониторинга — вероятно я бы и не узнал.
Но буду честен — утром я не придал значения этому. И как-то похуй было даже на уведомление )
И вот мне пишет чел — не работает.
Уже в обед.
И я решил проверить — и правда не работает.
Пошел ребутнул.
Не ребутается.
Ну думаю опять процессор перегрелся и сервак завис.
Отправляю на ручную перезагрузку сотрудником.
А через 15 минут сервер поднимается. И там пишут что сгорел Блок Питания
Неужели Хетзнеру трудно сделать так же как в ОВХ?
Это же конкурентное преимущество!