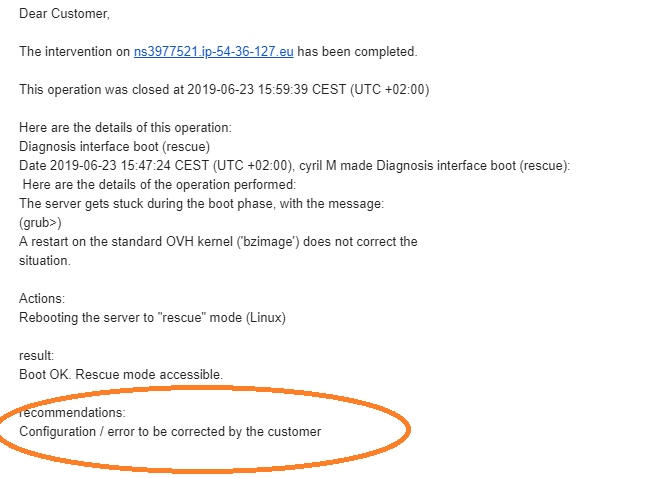
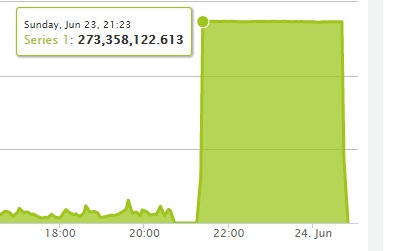
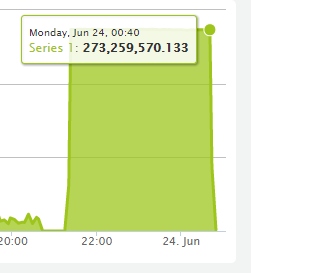
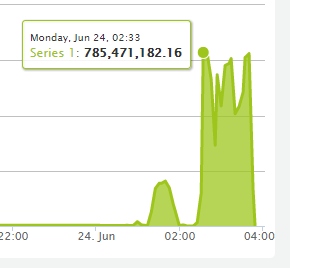
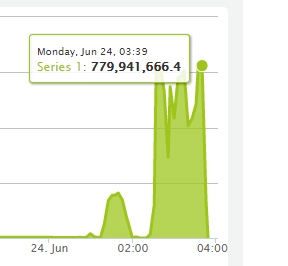
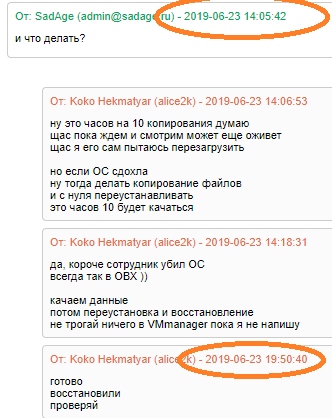
Сгорел дата-центр SBG2
История еще не завершилась и думаю еще пара недель уйдет на все это.
Следить за новостями можно тут
hosting.kitchen/ovh/datacenter-sbg.html

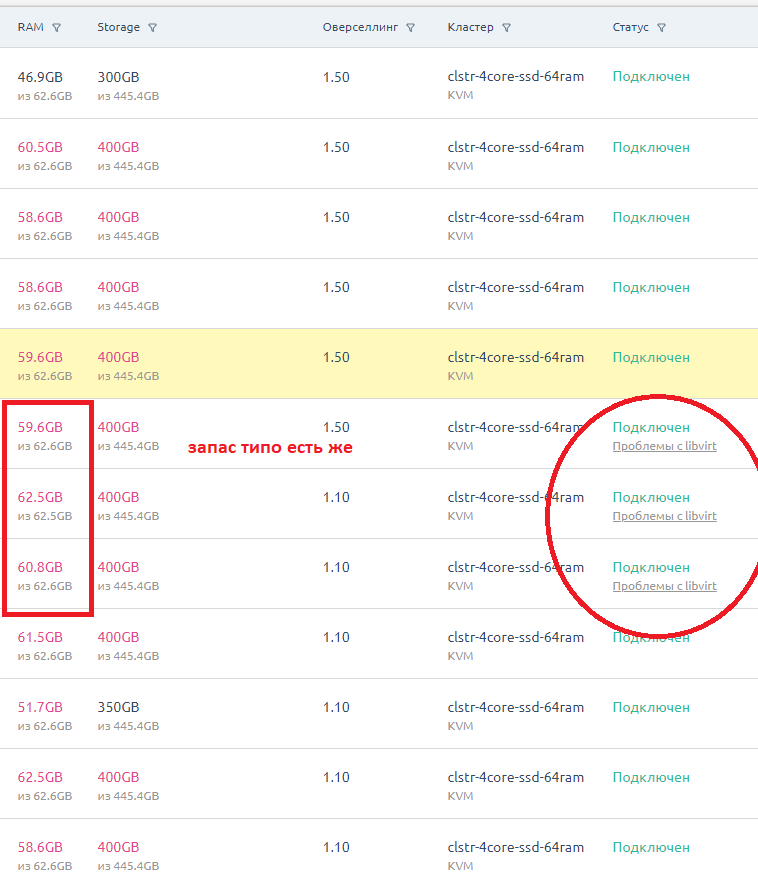
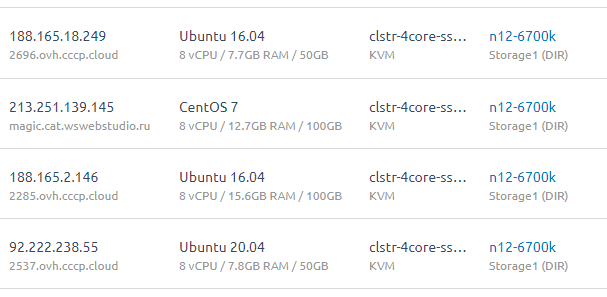
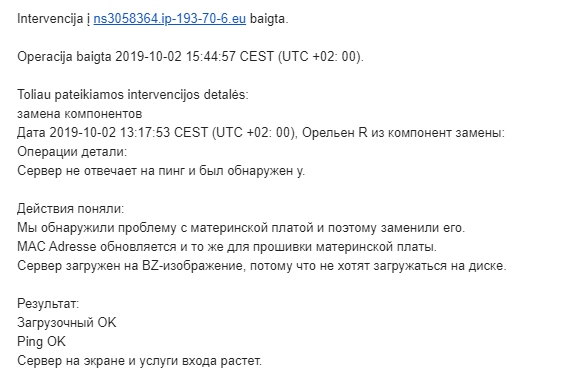
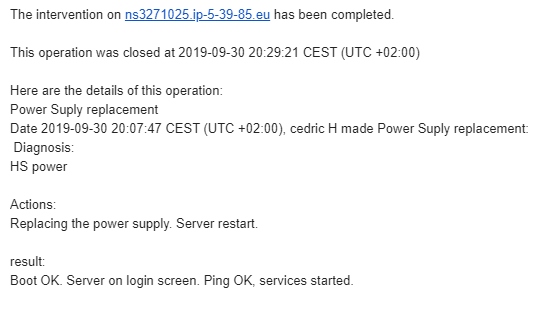
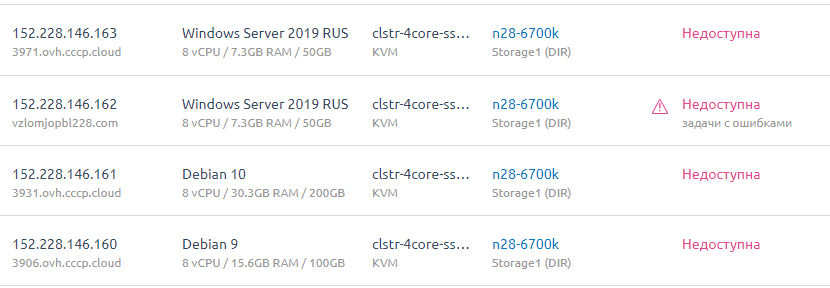
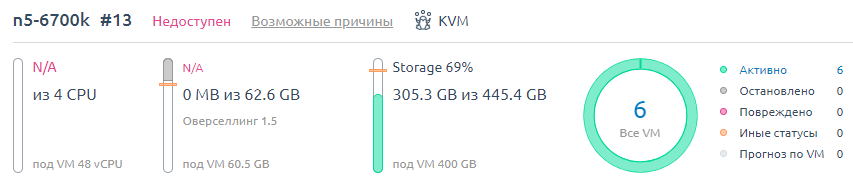
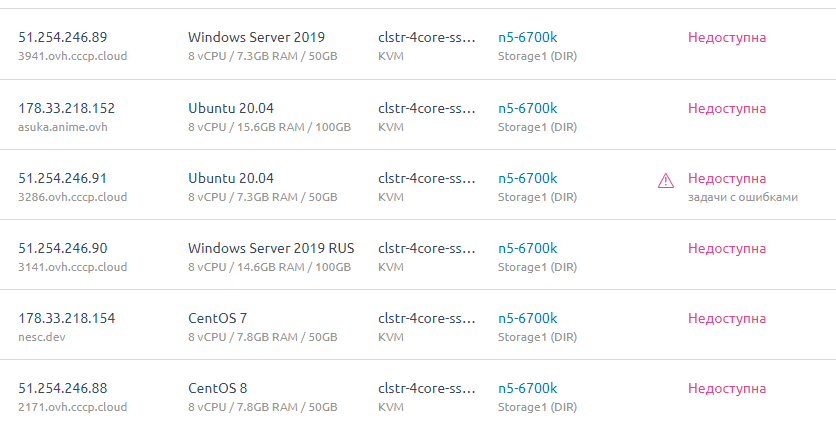
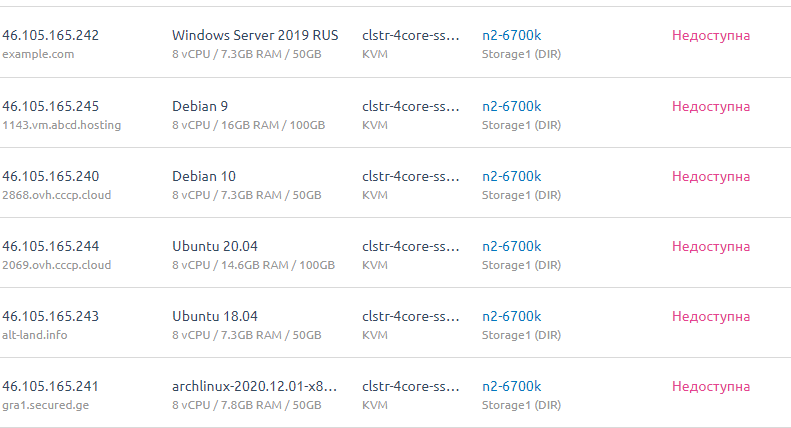
Итого, VM-ы которые сгорели. Или может быть потом что-то и восстановится посмотрим.
На данный момент считаем их погибшими.
Ryzen 7 SBG2 [VM-5]
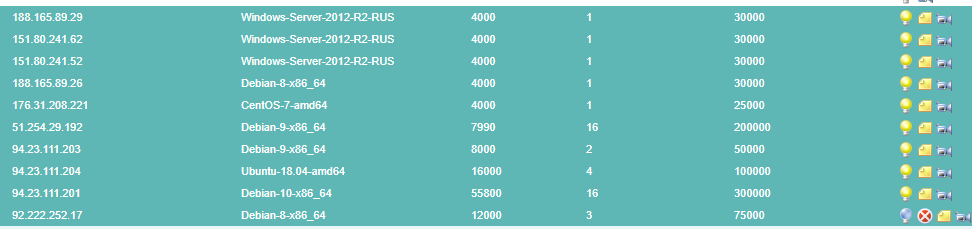
i7-6700k SBG2 [VM-5]

i7-6700k SBG2 [VM-6]



Следить за новостями можно тут
hosting.kitchen/ovh/datacenter-sbg.html
Итого, VM-ы которые сгорели. Или может быть потом что-то и восстановится посмотрим.
На данный момент считаем их погибшими.
Ryzen 7 SBG2 [VM-5]
i7-6700k SBG2 [VM-5]
i7-6700k SBG2 [VM-6]