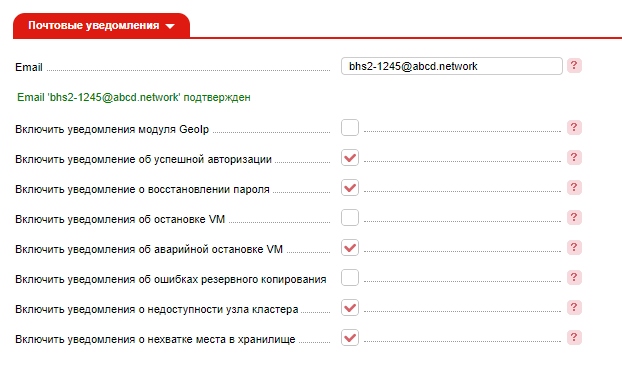
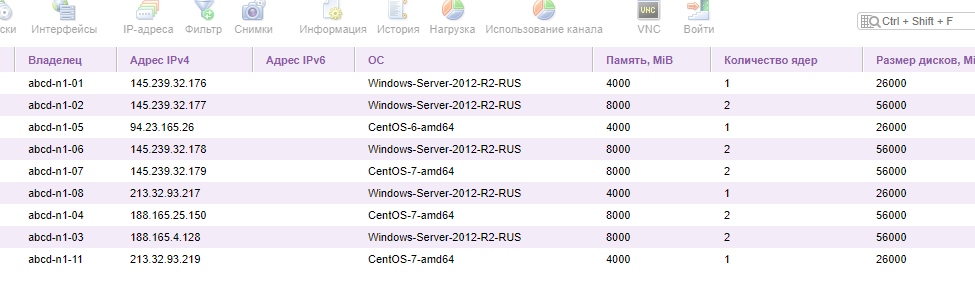
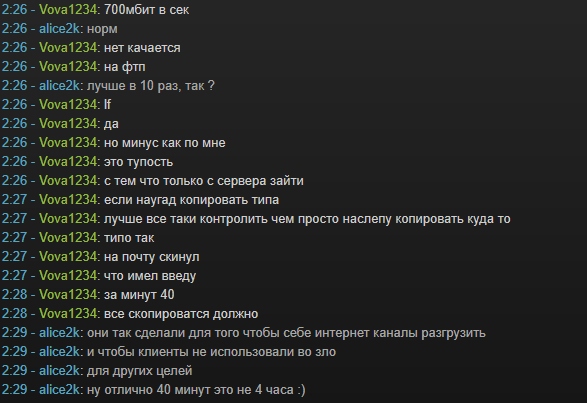
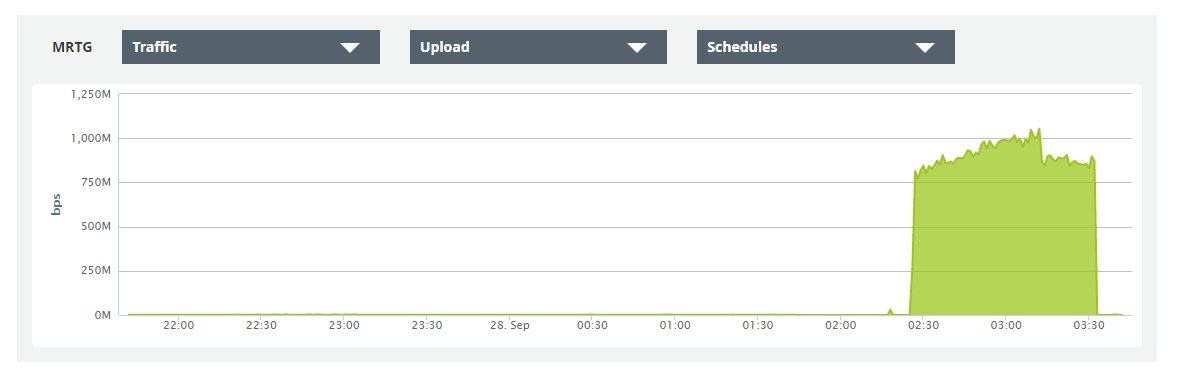
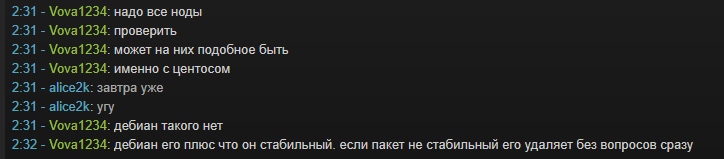
[vmmanager6] changelog 2020
[vmmanager6] changelog 2020
Читать дальше