v 2023.02.1 (01.02.2023) - кривое обновление
v 2023.02.1 (01.02.2023)
Новые возможности
Добавлена возможность использования двухфакторной аутентификации. Подробнее в документации: https://docs.ispsystem.com/x/mAFICg
Улучшения
Теперь вывод libvirt записывается в отдельный файл /var/log/libvirt/libvirtd.log.
Сокращена нагрузка на платформу от сервиса уведомлений.
Теперь единственная версия ОС Astra Linux, поддерживаемая для узлов кластера — Astra Linux 1.7.3.
Теперь единственная версия ОС Astra Linux, поддерживаемая для установки платформы — Astra Linux 1.7.3.
Улучшен механизм, определяющий количество ядер CPU на узле кластера.
Повышена безопасность функции "Антиспуфинг" за счёт блокировки RARP-трафика.
Исправление ошибок
Исправлена ошибка, из-за которой не удавалось выделить IPv6-подсеть после удаления VxLAN в кластере.
Исправлен текст ошибки, возникающей при коллизии MAC-адресов.
Исправлена ошибка, из-за которой при изменении гостевой ОС с Windows на Debian некорректно указывалось имя интерфейса в файле /etc/network/interfaces.
Исправлена ошибка, из-за которой включение SPICE на ВМ в кластере с типом сети IP-Fabric приводило к неработоспособности ВМ.
Исправлена ошибка, не позволявшая корректно определить тип ОС на узлах с CentOS 7.
Исправлена ошибка, не позволявшая производить настройку сети на узлах с ОС CentOS 7 из-за попытки установки ненужного пакета из репозитория.
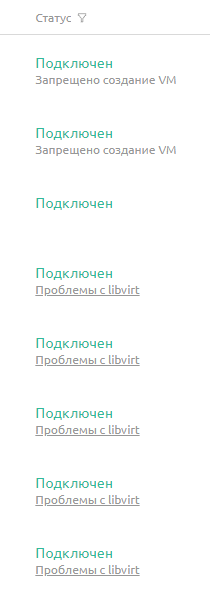
Исправлена ошибка, из-за которой при установке параметра узла "Запретить создание VM" оставалась возможность создать ВМ по API.
Исправлена ошибка, из-за которой в кластере с типом сети IP-Fabric на узле не обновлялись сетевые маршруты после добавления IP-адреса на ВМ.
Теперь при добавлении узла в кластер, если его имя совпадает с именем другого узла в платформе, формируется корректное уведомление.hosting.show/alice2k-hosting/gniloe-obnovlenie-vmmanager---v2023021.html