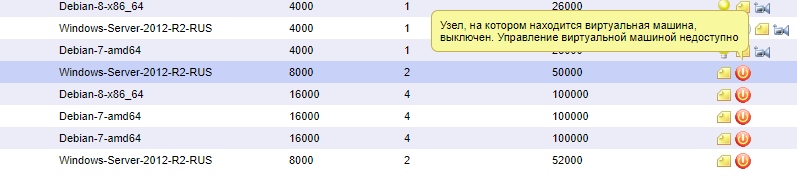
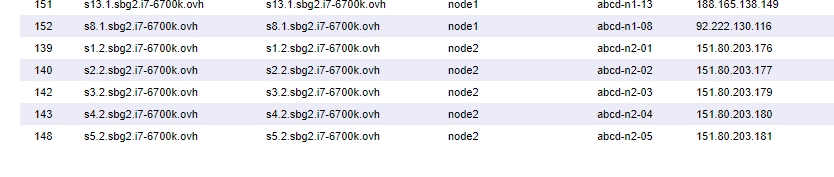
Просто в честные отчеты
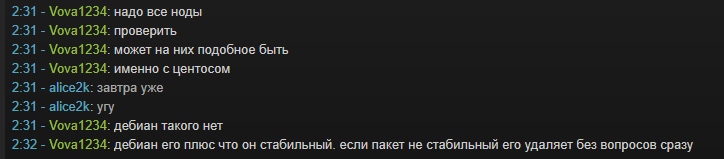
Трудно сказать связано ли это с обновлениями или нет.
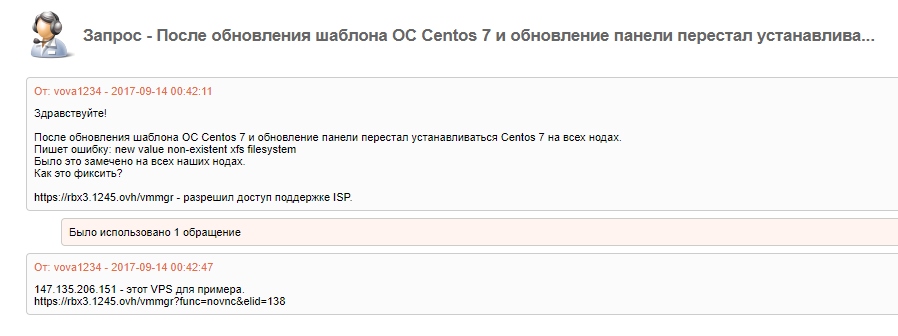
Но 30/11/2017
И вот 01/12/2017
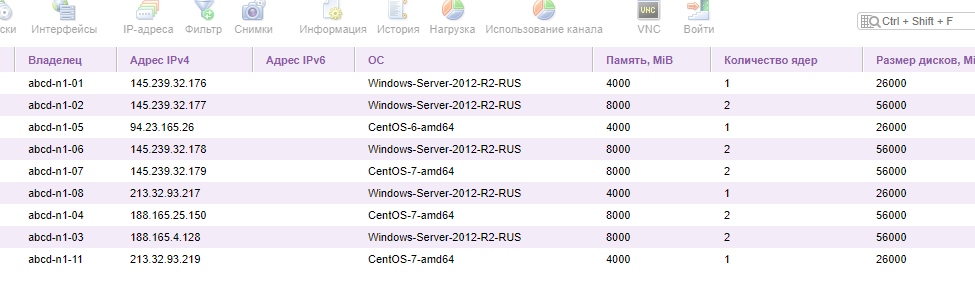
Некоторые ноды на CentOS зависают.
Не важно CentOS-6 ли это или CentOS-7
Зависают.
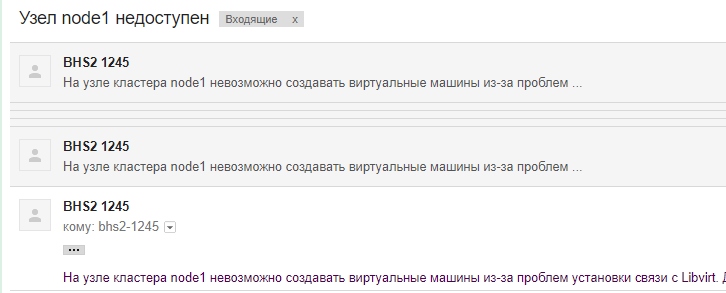
Не перезагружаются. Создается авто-тикет сотруднику ДЦ, что перезагрузка не удалась.

И потом вручную техник похоже что-то чинит и ребутает уже.
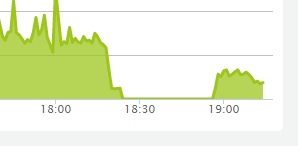
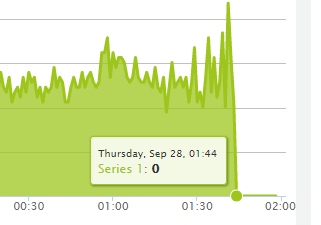
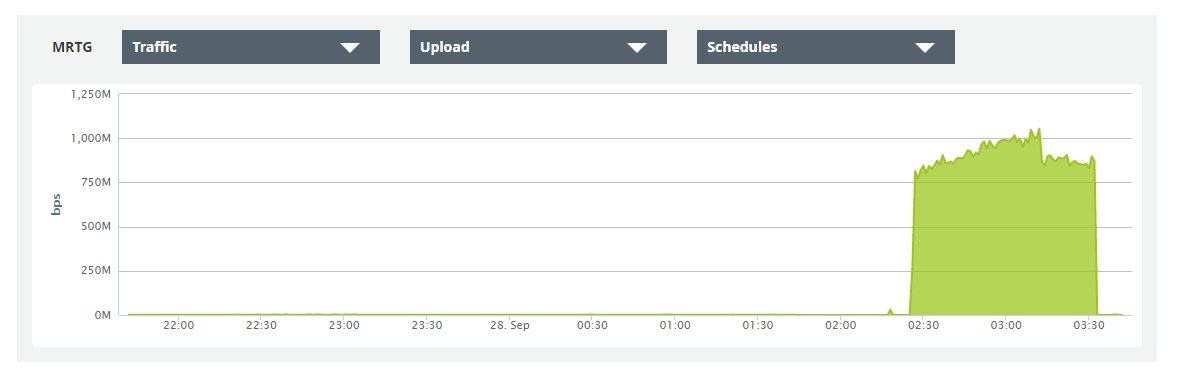
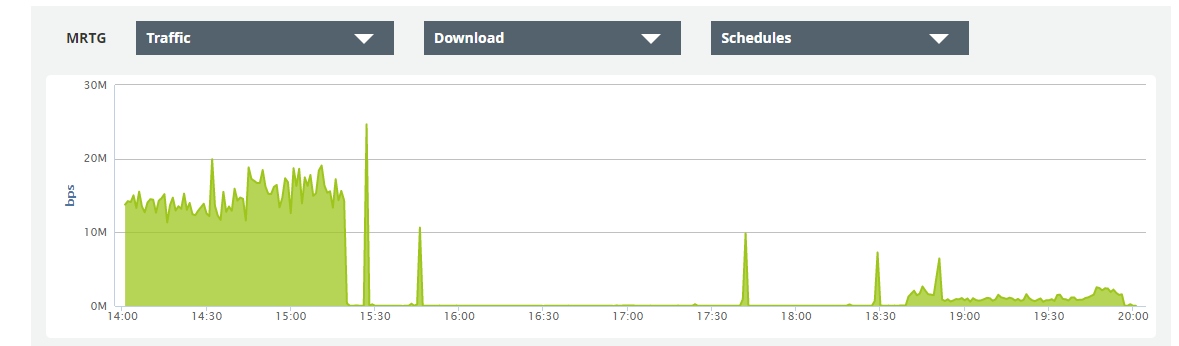
Так что вот, еще одно честное — падение.
От 15 до 40 минут простоя.
Причины — не известны.
В логах смотрели.
Сначала показалось что каких-то пакетов не хватало, поэтому зависло.
Потом админ сказал что больше похоже на панику ядра.
Но 30/11/2017
И вот 01/12/2017
Некоторые ноды на CentOS зависают.
Не важно CentOS-6 ли это или CentOS-7
Зависают.
Не перезагружаются. Создается авто-тикет сотруднику ДЦ, что перезагрузка не удалась.
И потом вручную техник похоже что-то чинит и ребутает уже.
Так что вот, еще одно честное — падение.
От 15 до 40 минут простоя.
Причины — не известны.
В логах смотрели.
Сначала показалось что каких-то пакетов не хватало, поэтому зависло.
Потом админ сказал что больше похоже на панику ядра.