Но вот сгорел один диск, правда не SSD, а NVME более новый и более современный, всего 2 года отслужил на 4 ТБ диск был. И я вспомнил что давно не проверял SSD где 6700k
Осень 2022 — пятый SMART отчет
Игнорируем все ноды где по 2 диска, смотрим только огнеопасные 6700k где 1 диск всего лишь.
Кстати в 2021 году еще и сам ДЦ SBG сгорел нахуй вместе с некоторыми нодами :) Прямо как я писал — работает, пока не сгорит :)))
Ну так вот смотрим только ноды, где 1 SSD без raid1:
В ОВХ каждая услуга под бесплатным мониторингом от ДЦ.
А кому он не нужен — в ПУ просто его отключают и тогда сотрудники ДЦ не трогают сервер вообще (который кстати меньше сотни обычно, а не по 500 человек как в РФ инженеров)
Так вот, когда в ОВХ сгорает что-то — 15 минут и готово — уже чинят, может быть пол часа, может быть час — все само, все автоматически потом сервер оживет.
А в Хетзнер — ты можешь даже и не знать о том, что сервер сдох.
В 10 утра сервер сдох. Если бы у меня не было своего мониторинга — вероятно я бы и не узнал.
Но буду честен — утром я не придал значения этому. И как-то похуй было даже на уведомление )
И вот мне пишет чел — не работает.
Уже в обед.
И я решил проверить — и правда не работает.
Пошел ребутнул.
Не ребутается.
Ну думаю опять процессор перегрелся и сервак завис.
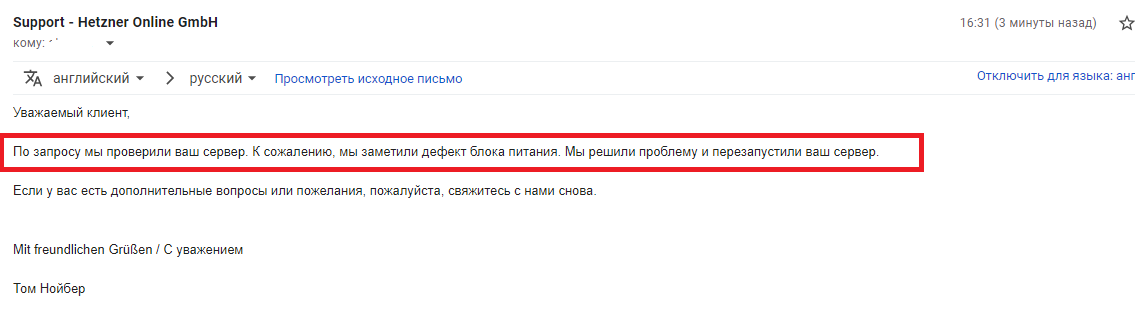
Отправляю на ручную перезагрузку сотрудником.
А через 15 минут сервер поднимается. И там пишут что сгорел Блок Питания
Неужели Хетзнеру трудно сделать так же как в ОВХ?
Это же конкурентное преимущество!