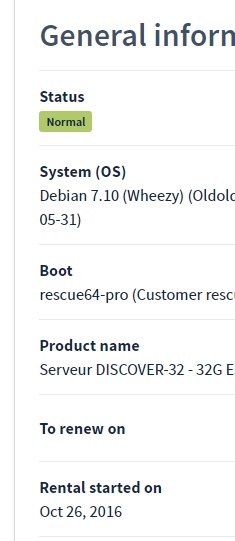
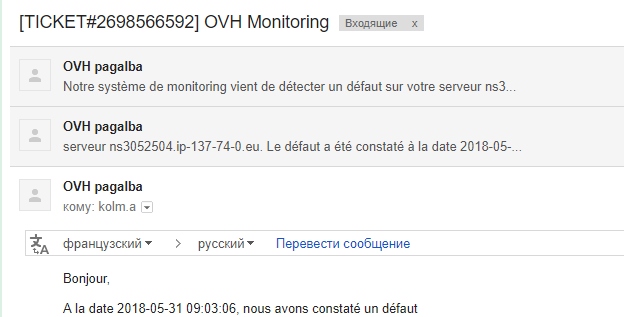
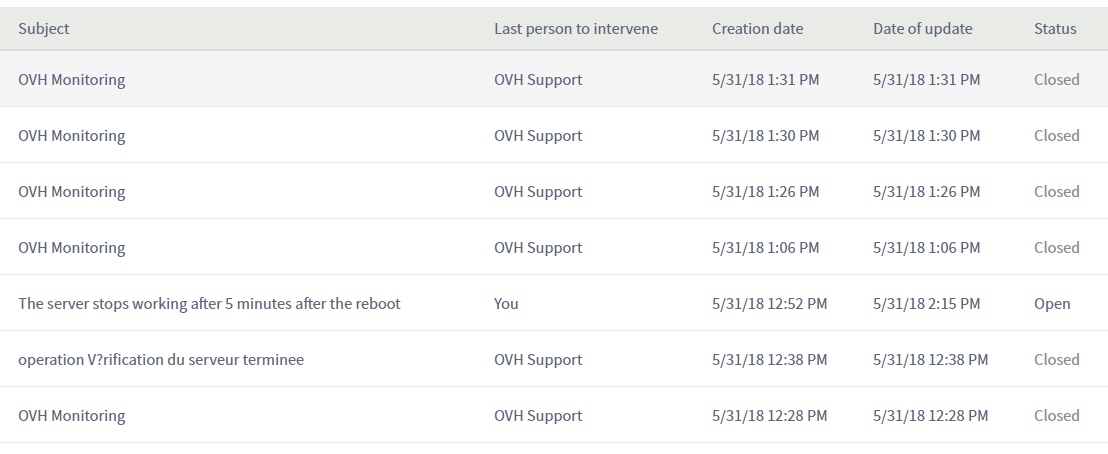
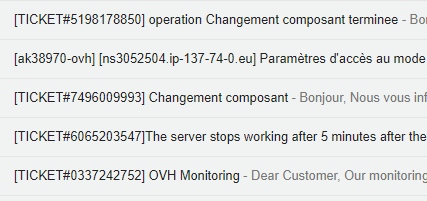
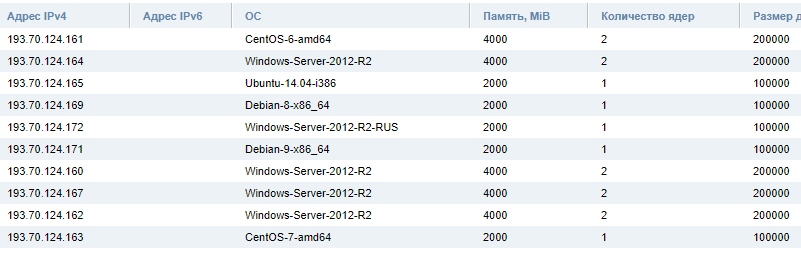
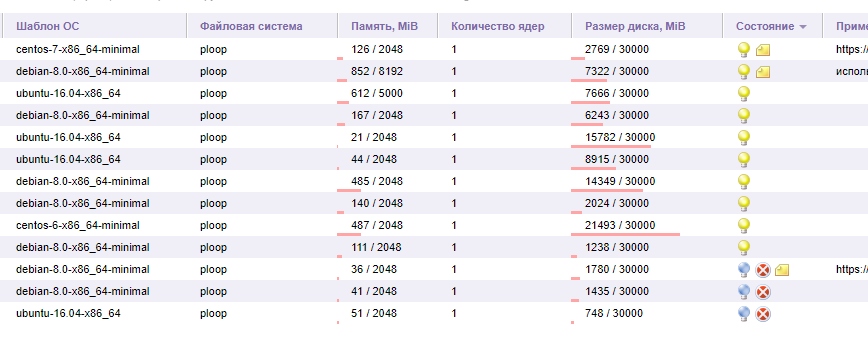
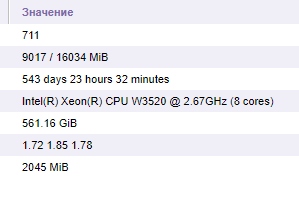
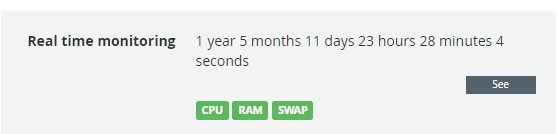
Статистка по ОС №2
Первая статистика была в самом начале
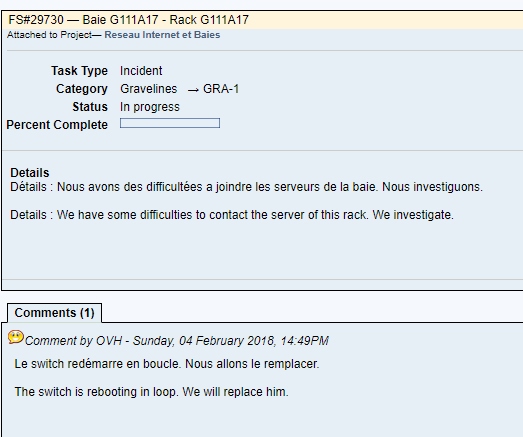
Решил вести паблик примеры [Осень 2017]
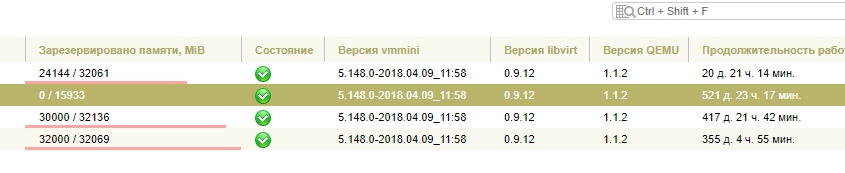
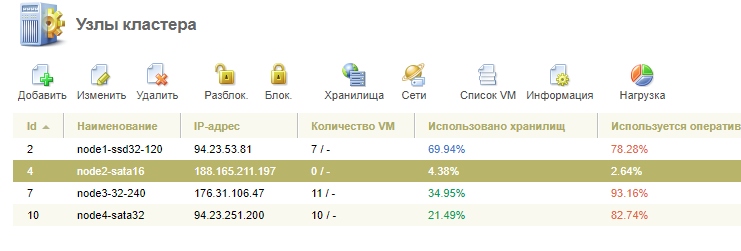
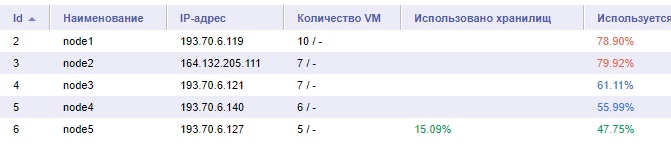
Теперь статистика на март 2019
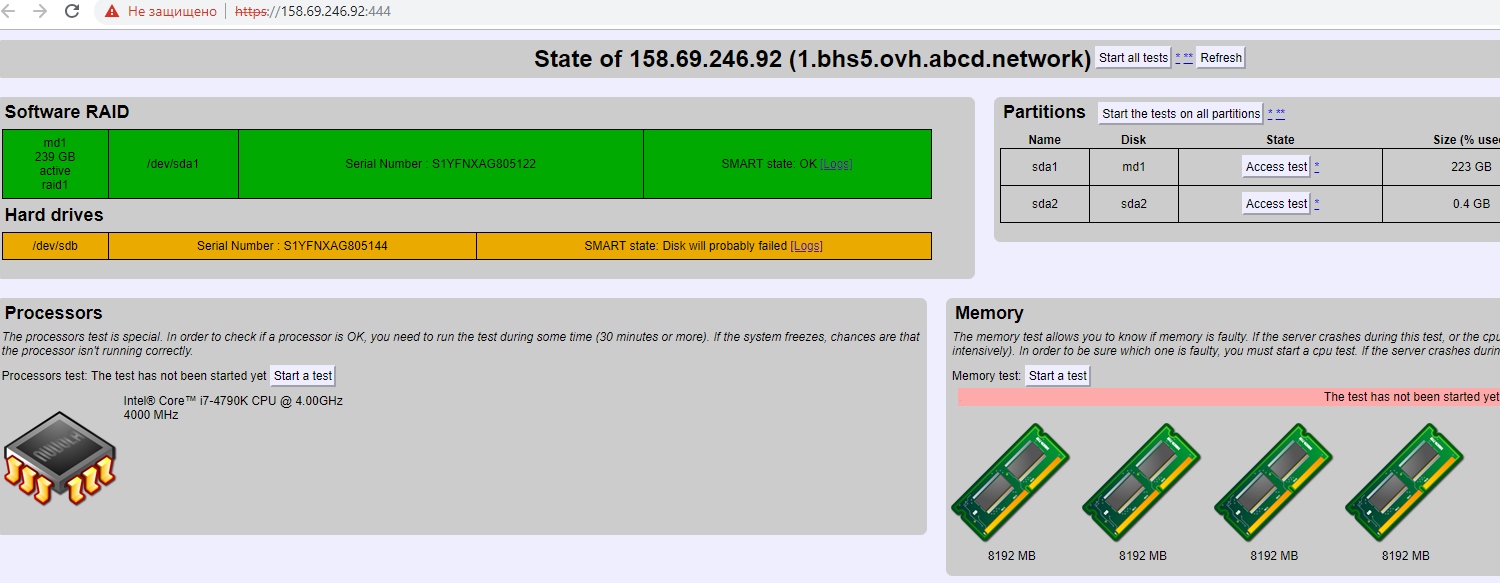
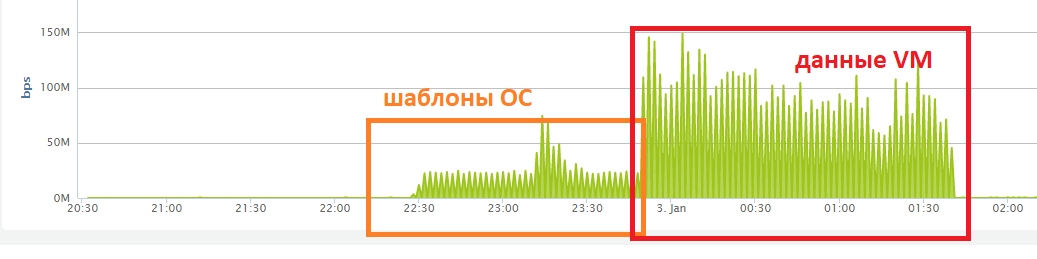
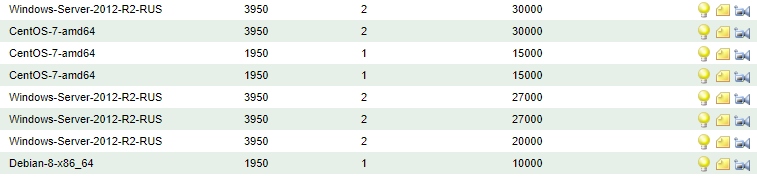
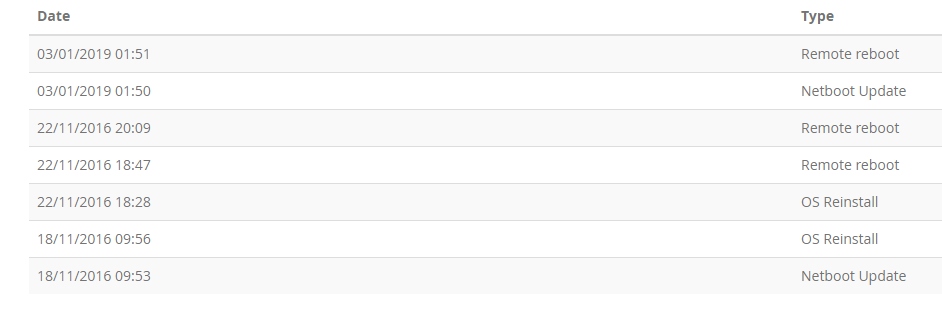
Нагрузку мы так и не поняли как нужно считать, поэтому просто положили хуй короче. Как говорится работает и ладно :) Оптимизацией не занимаемся.
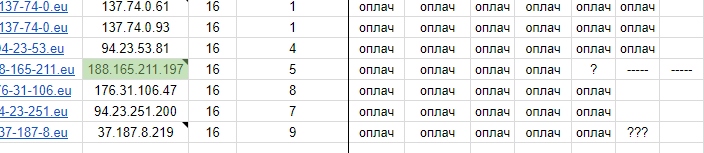
Как и написано в правилах услуги.
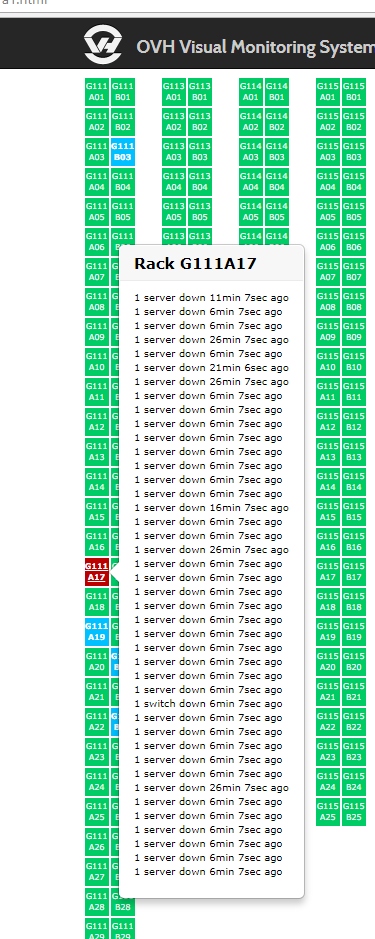
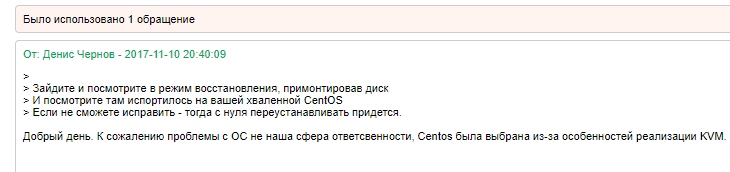
А теперь факты, просто факты.
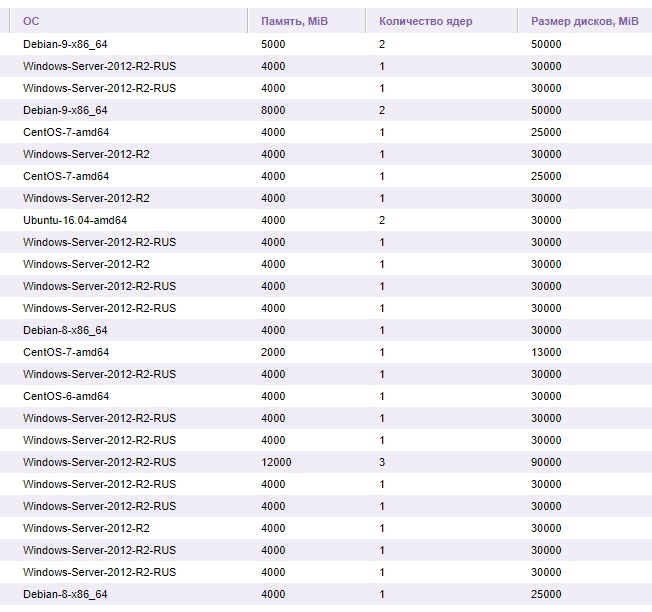
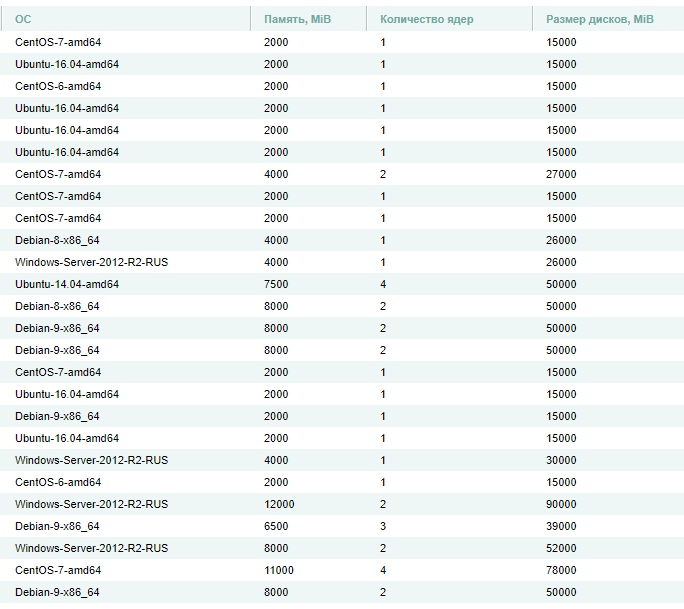
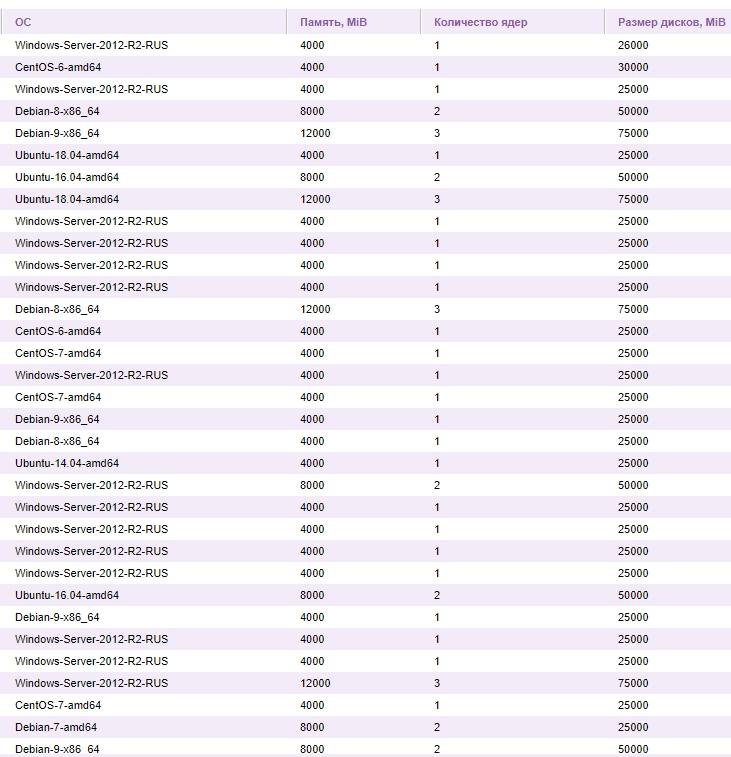
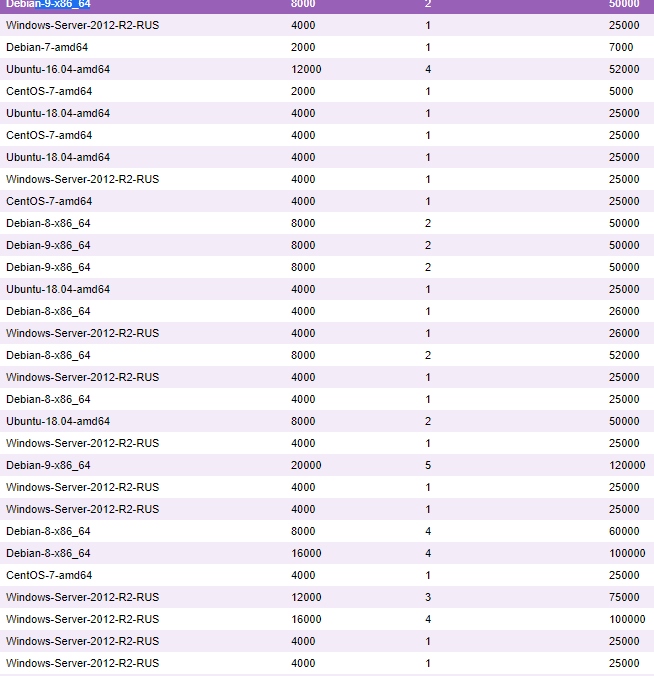
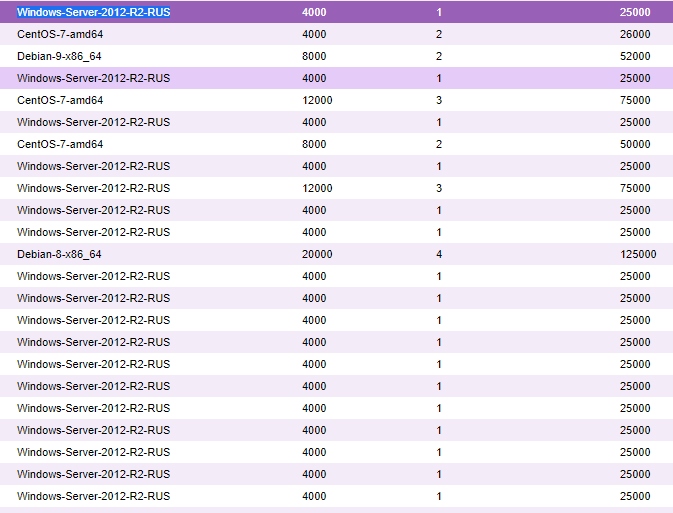
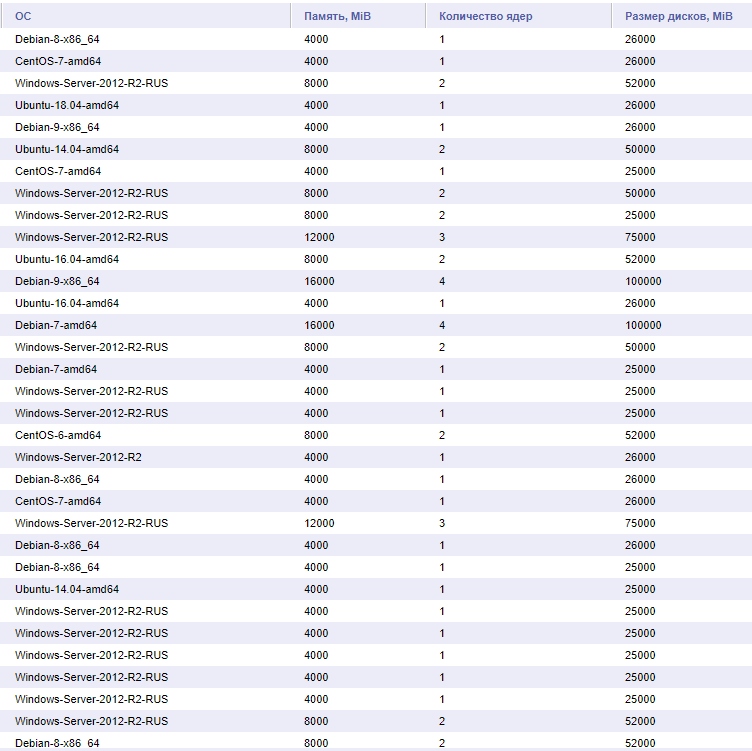
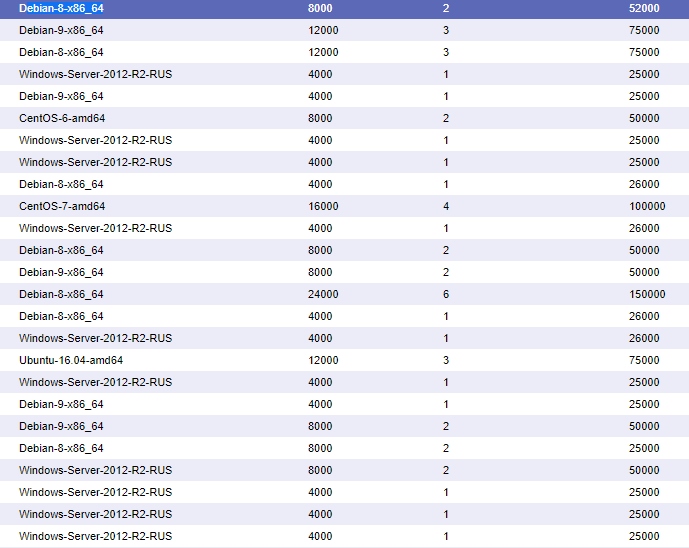
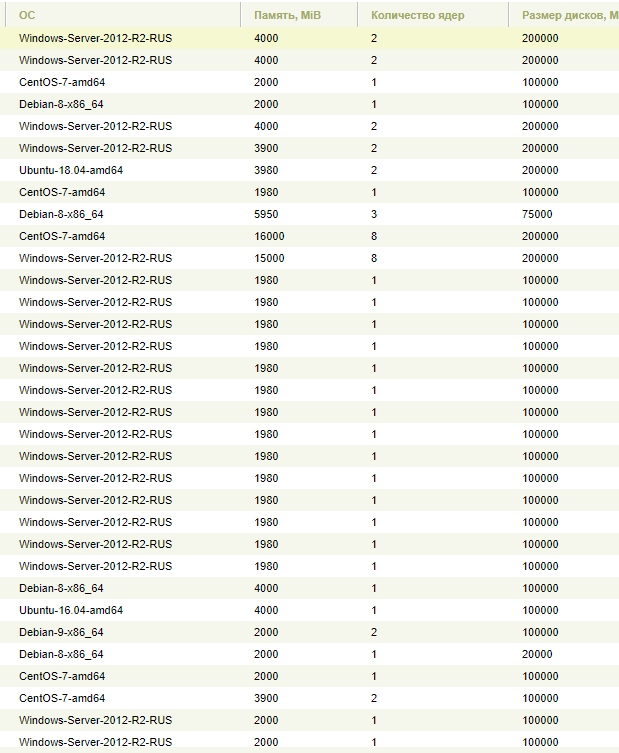
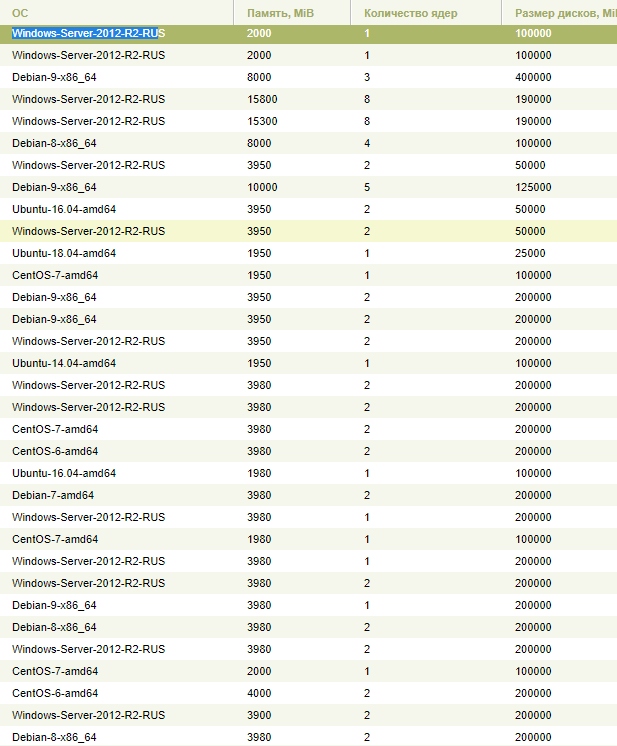
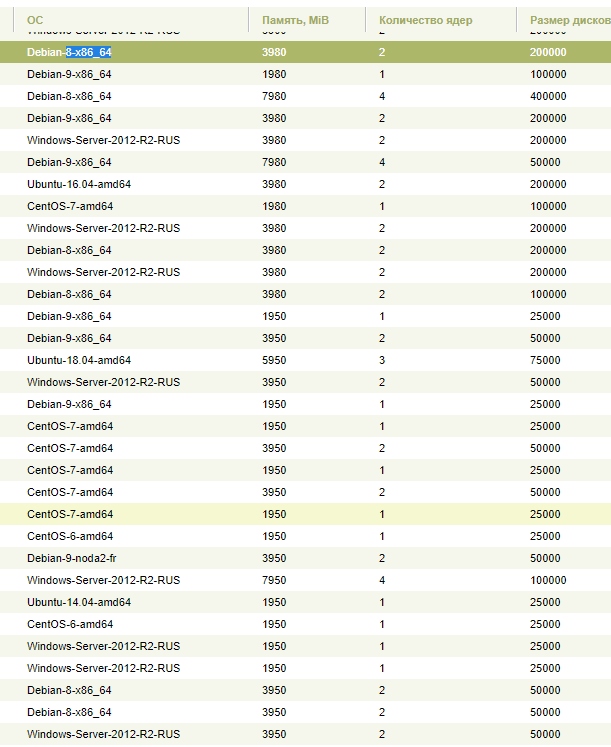
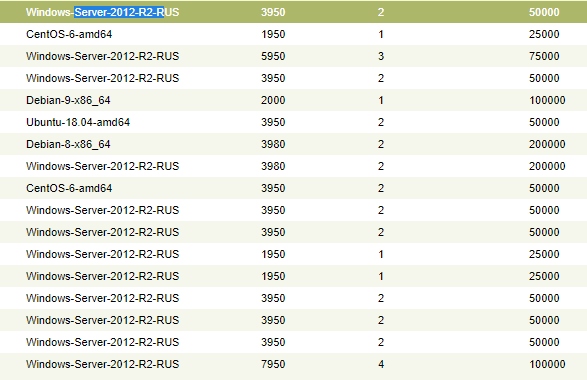
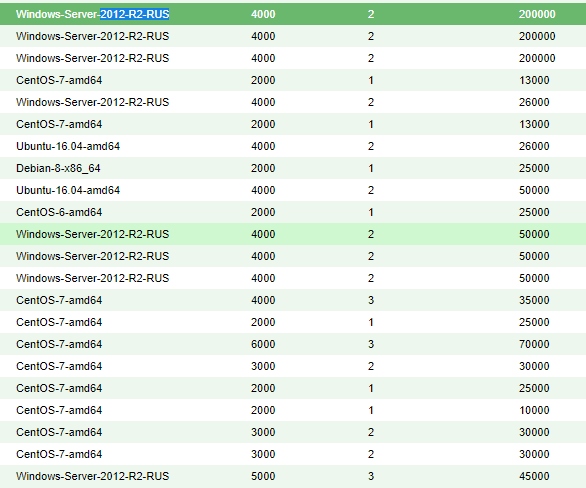
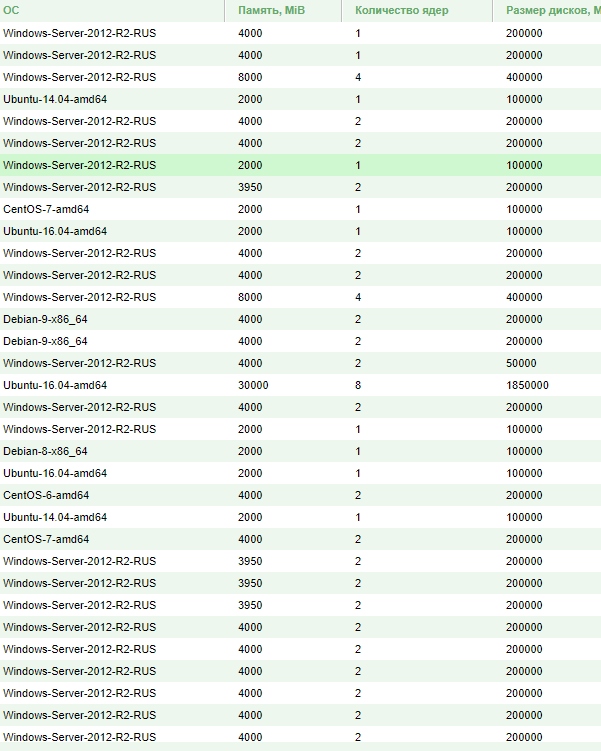
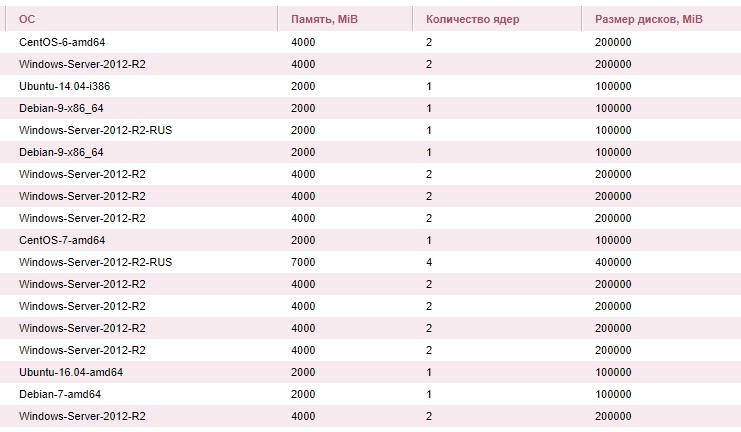
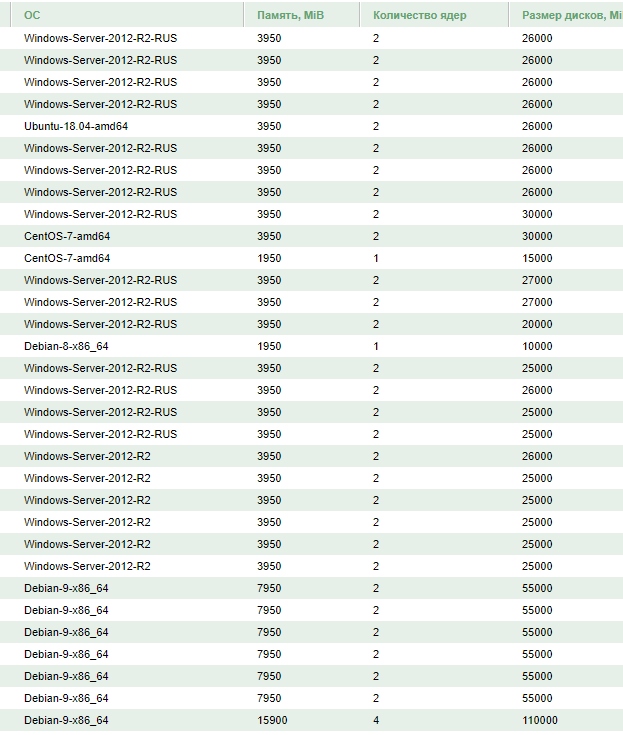
Решил вести паблик примеры [Осень 2017]
Теперь статистика на март 2019
Нагрузку мы так и не поняли как нужно считать, поэтому просто положили хуй короче. Как говорится работает и ладно :) Оптимизацией не занимаемся.
Как и написано в правилах услуги.
А теперь факты, просто факты.